
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 리프2기
- 자바스크립트
- 스위프트
- 카카오톡채팅봇
- 프로그래머스
- 인프런파이썬강의
- nodeJS
- 노드JS
- 파이썬중급강의
- rxswift
- swift
- 인프런강의
- SwiftUI
- Python3
- 파이썬
- 파이썬중급
- 웹크롤링
- 인프런
- JS
- 토플
- 파이썬웹크롤링
- uikit
- 교환학생토플
- 인프런오리지널
- IOS
- 인프런파이썬
- 유학토플
- IOS프로그래밍
- 우리를위한프로그래밍
- 토플공부수기
- Today
- Total
먹고 기도하고 코딩하라
Python Django 카카오톡 학식봇 만들기(2) - Amazon EC2에 firefox 웹드라이버 설치, 동적 웹페이지 크롤링하기 본문
Python Django 카카오톡 학식봇 만들기(2) - Amazon EC2에 firefox 웹드라이버 설치, 동적 웹페이지 크롤링하기
사과먹는사람 2020. 3. 4. 23:40이전 글 보기
카카오톡 학식봇 만들기(1) - 동적 웹페이지 크롤링 방법이 정적 웹페이지와 다른 이유
이전 시리즈 : 카카오 i 오픈빌더 챗봇 만들기 파이썬 장고로 카카오 i 오픈빌더 챗봇 만들기 (1) - 가상환경 설정, Django 프로젝트와 앱 만들기 Python Django 카카오 i 오픈빌더 챗봇 만들기 튜토리얼�
dev-dain.tistory.com
이번 포스팅에서는 Amazon EC2 컴퓨터에 웹 크롤링을 위한 이런저런 라이브러리를 설치해보고 직접 웹페이지를 크롤링하는 코드까지 짜는 것을 다룹니다.
굳이 Amazon EC2 컴퓨터일 필요는 없습니다. 그냥 Linux Ubuntu 환경이라면 가능하지만, Amazon EC2로 특정한 이유는 저의 작업 환경이기도 하고 CLI 환경이 아니면 이따 쓸 headless option 등이 굳이 필요하지 않기 때문이기도 합니다. 저의 예상독자들은 카카오톡 학식봇 만들기 이전 시리즈의 Python Django 로 카카오 i 오픈빌더 챗봇 만들기 시리즈를 모두 끝내고 오신 분들입니다. 아닌 분들도 참고 겸 읽어보셔도 좋습니다. ^^
그럼 시작하겠습니다. 가상환경을 활성화하시고, 위치는 /home/ubuntu 인 것을 확인해주세요.
일단 동적 웹페이지 크롤링을 하려면 웹 드라이버가 필요하다는 점은 이전 포스팅에서 설명했으므로 넘어가겠습니다. 크롬 드라이버를 설치할 수도 있고 phantom이나 다른 브라우저 드라이버를 설치할 수도 있지만 저는 firefox와 geckodriver를 설치하겠습니다. 다음을 입력합니다.
$ sudo apt-get update
$ apt-cache show firefox | grep Version
- Version: 73.0.1+build1-0ubuntu0.16.04.1
- Version: 45.0.2+build1-0ubuntu1
$ sudo apt-get install firefox=73.0.1+build1-0ubuntu0.16.04.1
$ sudo apt-mark hold firefox
일단 apt-get update 를 해줍니다.
apt-cache 는 ubuntu 환경에서 소프트웨어나 라이브러리를 검색하는 명령어입니다. show 는 그 다음 인자와 관련된 패키지를 볼 수 있는 명령어이고요. 쉽게 말해 우리가 입력한 명령어는 firefox 와 관련된 패키지들을 보여달라는 겁니다. grep 은 파일에서 패턴을 찾아주는 명령어입니다. Version 이라는 단어가 들어 있는 라인을 보고 싶을 때 쓸 수 있는데요. 저의 경우 ubuntu 16.04 LTS 컴퓨터를 받아서 쓰고 있습니다. 73.0.1 버전을 사용할 수 있을 것 같네요.
apt-get 해서 firefox를 설치하는데 첫 줄의 Version과 똑같은 것으로 받습니다. 그대로 입력하시면 됩니다.
apt-mark hold는 특정 패키지의 버전을 홀딩하는 명령어입니다. 쉽게 말하면 업데이트에서 제외시키는 명령어입니다. sudo apt-get를 하면 자동으로 업데이트될 때가 있잖아요? 그럴 때 자동 업데이트되는 것을 막으려고 입력하는 명령어입니다. 여기서는 갓 설치한 firefox의 버전 유지를 위해 입력합니다.
이제 firefox 를 설치했습니다. 이제 firefox 웹 드라이버인 geckodriver 를 설치해야 할 차례입니다.
다음을 입력하기 전에 한 가지 확인하셔야 할 게 있습니다. geckodriver 는 Mozilla github 에서 직접 다운로드하게 되는데 어느 버전까지 나왔는지 확인하고 받으셔야 뒷탈이 없습니다. 옛날 포스팅을 보고 firefox 는 최신으로 다운로드했는데 드라이버를 구 버전으로 깔게 될 가능성이 있습니다. 이왕이면 최신 버전으로 설치해 보겠습니다.
일단 여기로 접속해서 최신 버전을 확인해봅니다. 제가 설치하는 지금(2020년 3월 1일)은 v0.26.0이 가장 최근 버전이네요. 저는 이 버전으로 설치하겠습니다. 스크롤을 내려서 geckodriver-v0.26.0-linux64.tar.gz 라고 된 파일 링크를 땁니다. 이 링크로 다운로드를 해보겠습니다.
다음을 입력합니다.
$ wget https://github.com/mozilla/geckodriver/releases/download/v0.26.0/geckodriver-v0.26.0-linux64.tar.gz
$ tar -zxvf geckodriver-v0.26.0-linux64.tar.gz
wget 은 리눅스 환경에서 인터넷에서 파일을 받아야 할 때 가장 좋은 방법입니다. 이런 건 pip 이나 apt 로 받을 수 없거나 받기 힘들기 때문에 wget 으로 받는 것이 좋습니다. 사용법은 wget 다음에 링크를 입력하는 것입니다. 아까 링크를 wget 인자로 줍니다. 그러면 geckodriver 압축 파일을 받을 수 있습니다.
tar -zxvf 는 압축 파일을 해제하는 명령어입니다. -zxvf 옆에 압축 파일의 이름을 적으면 압축 해제가 됩니다. 이 명령어를 실행하면 geckodriver 하면서 까져서 나옵니다. 이 다음에는 원본 압축 파일은 지우셔도 상관 없습니다.
다음을 입력합니다.
$ sudo pip3 install --upgrade pip
$ pip3 install selenium
$ sudo apt-get install python3-bs4
$ pip3 install BeautifulSoup4
$ pip3 install lxml
pip 버전을 업그레이드해줍니다. 그런 다음 selenium 을 설치하는데요. 이 때 그냥 pip 이 아니라 pip3을 쓰는 이유는 python2.7 버전이 있을 때 그냥 pip 을 쓰면 python2.7에 맞는 게 설치되기 때문입니다. 꼭 pip3을 써주세요.
그런 다음 python3-bs4 를 설치해주고, BeautifulSoup4 도 설치해줍니다. lxml 도 설치해주는데 lxml 은 쉽게 말해 XML 파싱 모듈입니다. XML 은 일종의 마크업 언어인데 HTML 이 가장 대표적인 XML 의 예입니다. lxml 은 모듈을 설치해야 하지만 상대적으로 속도가 빠르다는 장점이 있습니다. 사실 저는 초보인지라 html.parser 와 속도 차이가 나는 걸 잘 못 느끼겠지만 찾아야 할 양이 많아질 때는 그 효과를 체감할 수 있겠습니다.
사실 기본적으로 제공되는 html.parser 로 파싱도 됩니다. lxml 이 아니라 html.parser 를 사용하실 분들은 맨 아래 lxml 설치 명령어는 하지 않으셔도 좋습니다.
이제 거진 준비가 다 되었습니다.
입력 전에 참고하십시오. 저는 일부러 여러 함수로 쪼개지 않는 것을 선택했습니다. 원래는 다 쪼개 놓는데 보시기 편하라고 일부러 순서대로 작성했습니다. 이 파일은 테스트용으로 만든 것이며 실제 쓰는 파일은 함수별로 다 쪼개 놓은 파일입니다. 그러므로 튜토리얼을 건너뛰실 분은 이것을 실행하지 않고 바로 여기를 참고하면 됩니다. 실제로 쓰는 파일의 go_crawl() 함수에 대해서는 다음 시간에 짧게 다루겠습니다.
그냥 눈으로 보셔도 되고 입력하셔도 됩니다.
$ vi test.py
# test.py
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.firefox.options import Options
from time import sleep
import os
import sys
options = Options()
options.headless = True
driver = webdriver.Firefox(options=options)
url = 'http://www.duksung.ac.kr/diet/schedule.do?menuId=1151'
driver.get(url)
driver.implicitly_wait(5)
sleep(3)
#sleep이 있어야 dietTime class와 dietNoteContent id 콘텐츠를 볼 수 있음
html = driver.page_source
soup = BeautifulSoup(html, 'lxml')
target_table = soup.find(id='schedule-table')
info_str = target_table.find_all("th")
for i in range(len(info_str)):
info_str[i] = info_str[i].get_text('\n')+'\r\r'
meal_str = target_table.find_all("td")
for i in range(len(meal_str)):
meal_str[i] = meal_str[i].get_text('\n')+'\r\r'
if os.path.exists('week_meal.txt'):
os.remove('week_meal.txt')
if os.path.exists('week_info.txt'):
os.remove('week_info.txt')
meal_fp = open('week_meal.txt', 'w', encoding='utf-8')
meal_fp.writelines(meal_str)
meal_fp.close()
info_fp = open('week_info.txt', 'w', encoding='utf-8')
info_fp.writelines(info_str)
info_fp.close()
driver.close()
하나씩 볼까요? 일단 BeautifulSoup, webdriver, Options, sleep 등을 import 합니다. selenium 을 전체 다 import 하지 않고 webdriver 와 Options 만 import 한 이유는 selenium 이 정말 그 정도밖에 필요없기 때문입니다. ^^ os와 sys 도 같이 import 해줍니다.
일단 Options 를 받는데요, headless를 True로 하는 게 목적입니다. headless 는 브라우저를 렌더링하지 않고 그냥 작업하기 위한 옵션입니다. 우리 CLI에서는 어차피 렌더링이 되지도 않으므로 headless True가 필수입니다.
그 다음 driver 를 받습니다. Firefox 웹드라이버를 받는데 options 는 아까 만들어둔 headless options 로 줍니다.
url 은 매개변수로 직접 줘도 되지만 그러면 별로 그림이 안 좋으니까 따로 변수를 할당했습니다.
driver 에서 url 로 get을 하면 그 url 웹페이지를 로드하는 것과 같습니다. 그 다음 바로 implicitly_wait(밀리세컨드 단위)를 합니다. 브라우저 JS 엔진에서 웹페이지를 파싱하는 시간을 기다려주는 건데요. 추가로 sleep 도 권합니다. 프로세스 자체를 잠깐 재워서 지연시키는 건데요. JS에 의해 페이지 로딩이 끝날 때까지 기다려주는 역할을 합니다.
그런 다음 driver 에서 page_source 를 하면 페이지 소스 코드 전체를 받게 됩니다. html 변수에 저장시켜 주시고요.
이제 본격적으로 BeautifulSoup 를 쓸 차례입니다. 이 부분은 이 포스팅에서 자세히 다뤘으니 따로 설명하지 않겠습니다.
웹 드라이버는 반드시 close 해줘야 하는 것을 잊지 맙시다.
다 됐다면 한 번 실행해 볼까요? 그런데 저는 이런 메시지가 나오면서 실행되지 않았습니다.
"'geckodriver' executable needs to be in PATH"
geckodriver 가 PATH에 없어서 실행이 안 됐다는데요. 이에 관한 질문이 스택오버플로우에 있었고 많은 좋은 답변들이 있었습니다. 가장 정통적인 방법은 bash 에서 다음과 같이 PATH 를 export 해 주는 해결법일 것입니다.
export PATH=$PATH:/path/to/directory/of/executable/downloaded/in/previous/step
# 내가 실제로 한 것
# chmod +x geckodriver
export PATH=$PATH:/home/ubuntu/geckodriver/.
sudo cp geckodriver /usr/local/bin
일단 chmod 는 어떤 파일이나 디렉토리에 대한 권한을 제어하는 명령입니다. 모든 사용자에게 실행 권한을 추가하는 게 +x 인데요. 지금 생각해보니 굳이 안 해도 될 것 같아서 주석 처리했습니다. 동일 오류가 생긴다면 chmod 도 해보세요. geckodriver PATH 를 설정해줍니다. 저는 여기에 geckodriver 를 /usr/local/bin 에 복사하기까지 했습니다. 이 폴더에 복사한 이유는 이 포스팅에 자세히 나와 있는데요. 요약하자면 /usr/local/bin 에 복사한 것은 아까 firefox 에서 apt-mark hold 를 한 것과 같은 이유입니다.
이렇게 하고 난 다음 다시 실행을 해 보면 정상적으로 실행이 될 것입니다. 만약 에러 메시지가 뜬다면 오타 등의 오류일 수 있습니다. 제 경우 'invalid argument: can't kill an exited process' 하면서 에러가 나와서 검색해 보니 firefox 와 geckodriver 버전이 호환되지 않아서 그럴 거라는 답변들을 보고 의아했는데요, 알고 보니 headless를 haedless 라고 잘못 쓴 거였습니다(;;). 고쳐준 다음에는 정상 실행되었습니다.
2020년 3월 4일 기준 제 실행 결과는 다음과 같습니다.

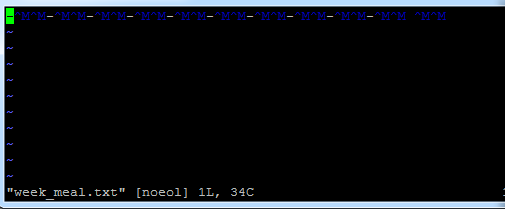
현재 개강이 미뤄져 학식이 나오지 않다 보니 week_meal 파일은 모두 '-' 자로 비워져 있습니다. 잘 보이지 않겠지만 for 루프를 돌릴 때 각 원소마다 캐리지 리턴을 두 번 넣어준 것이 '^M'으로 표시되어 있습니다. 이는 나중에 views.py 에서 이 텍스트 파일을 불러와 split 할 때 유용하게 쓰일 것입니다. 다음에 views.py 를 수정할 때 다시 다뤄 보겠습니다.
다음 포스팅에서는 크롤링을 담당하는 이 파일의 완성판을 보고 views.py 에서 이 텍스트 파일을 어떻게 써야할지 다뤄보겠습니다.
읽어주셔서 감사합니다. ^^
다음 글 보기
카카오톡 학식봇 만들기(3) - 텍스트 파일 파싱해서 메시지로 보내기
안녕하세요? 이번 포스팅에서는 저번 포스팅에서 다뤘던 크롤링 코드 파일의 완성판을 한 번 같이 보고 실행 결과인 텍스트 파일을 views 에서 잘 가공하는 방법을 다뤄 보겠습니다. 먼저 가상환�
dev-dain.tistory.com
Reference
Selenium using Python - Geckodriver executable needs to be in PATH
[Wiki] '/bin' 디렉토리와 '/usr/bin' 디렉토리의 차이는 무엇일까? ('/bin' vs '/usr/bin')
'개발일지' 카테고리의 다른 글
| Python Django 카카오톡 학식봇 만들기(4) - views 완성, 시나리오와 블록에 스킬 적용하기 (1) | 2020.03.07 |
|---|---|
| Python Django 카카오톡 학식봇 만들기(3) - 텍스트 파일 파싱해서 메시지로 보내기 (0) | 2020.03.05 |
| 웹 소스 코드 보며 beautifulsoup4 문법 익히기 (2) | 2020.03.03 |
| Python Django 카카오톡 학식봇 만들기(1) - 동적 웹페이지 크롤링 방법이 정적 웹페이지와 다른 이유 (0) | 2020.03.02 |
| 파이썬 장고로 카카오 i 오픈빌더 챗봇 만들기 (4) - 카카오 오픈빌더와 챗봇 서버 연동하기 (2) | 2020.03.01 |



