
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 교환학생토플
- 토플
- 유학토플
- 토플공부수기
- 카카오톡채팅봇
- 우리를위한프로그래밍
- 파이썬중급강의
- swift
- 인프런강의
- 인프런
- nodeJS
- 프로그래머스
- 리프2기
- 웹크롤링
- 파이썬중급
- SwiftUI
- Python3
- 스위프트
- 인프런오리지널
- IOS프로그래밍
- uikit
- 파이썬
- 노드JS
- 인프런파이썬강의
- JS
- 자바스크립트
- IOS
- 인프런파이썬
- 파이썬웹크롤링
- rxswift
- Today
- Total
먹고 기도하고 코딩하라
[인공지능] 로이터 뉴스 카테고리 분류 과제 본문
작년 2학기에 들었던 <인공지능> 강의 기말 과제는 로이터 뉴스 데이터셋으로 카테고리를 분류하는 과제였다.
그 전에는 Cifar-10 Fashion 데이터셋을 CNN으로 분류하는 과제를 했는데, 결과가 그렇게 좋지는 않았다. 과제 점수에서 18점 이상 받은 학생들은 도대체 어떻게 한 건지 지금까지도 궁금하다. ^^
로이터 뉴스의 경우 데이터 간 순서가 있고, 이 순서가 중요하다. CNN만으로는 분류를 잘 할 수 없다. 그래서 RNN(Recurrent Neural Network), 순환신경망을 쓰게 된다. CNN과 RNN의 다른 점은 CNN이 정적인(static) 입출력 map이라면 RNN은 동적인(dynamic) 입출력 map이라는 것이다. 이전의 모든 시간 입력을 고려하는 모델이다.
쉽게 말해 RNN을 쓰기 적합한 데이터는 순서가 굉장히 중요한, sequential한 데이터이다. 주로 음성, 문장(자연어), 심전도 신호 등이 여기 들어가게 된다. 가끔 주식 시장 종가나 지수 예측하는 프로그램을 만들 때도 쓰는 것 같다. 한 7일 정도의 시장의 여러 가지 지수를 가지고 오늘, 다음 날의 지수를 예측하는 것이다.
단, 단순 RNN만으로는 문제가 있다. MLP(Multi Layer Perceptron, 다층 퍼셉트론)에서 나타난 Vanishing Gradient 문제가 발생하는데, 입력층과 출력층 사이의 은닉층이 깊어질수록 가중치가 점점 줄어들어 0에 가까워지는 문제이다. 그럴 수밖에 없다. 가중치에 1보다 작은 값이 계속 곱해지니 가중치가 줄어드는 것이다. 이렇게 하면 weight 변경이 의미있는 수준으로 일어나기 어렵고, 그래서 적합한 모델을 찾기 어려워진다.
이에 대한 해결으로 LSTM(Long Short Term Memory)이 있다. 은닉층과 시간에 대해 가중치값 감소를 제어할 수 있는 것이다. RNN은 시간이 지나면 이전 입력값을 잊어버리지만, LSTM은 이전 입력값 정보가 다음 상태 메모리에 계속 반영된다. 은닉 노드에 입력, 기억, 출력 게이트가 달려 있어 어떤 노드에서 입력 게이트를 닫아 두면 이전 노드에서 받은 정보를 계속 기억할 수 있는 것이다.
LSTM은 입력/기억/출력 정도를 조절하는 3개의 게이트로 구성되며 RNN과 달리 셀(Cell)이 추가되어 있다. 입력은 Input, 기억은 Forget, 출력은 Output 게이트에서 각각 담당한다. 바이너리 값으로 입력을 받을지/버릴지, 기억할지/버릴지, 출력할지/말지를 결정한다. 시간에 대한 은닉층을 메모리 셀이라고 하는데, 이 cell state를 3개의 게이트로 보호하고 제어한다.
이외에 LSTM을 간단한 구조로 만든 GNU, CNN + LSTM 등이 있다.
시작
일단 텐서플로 2 버전을 선택하고, 텐서플로와 numpy, pyplot, os 등 필요한 모듈들을 가져온다.
try:
# %tensorflow_version only exists in Colab.
%tensorflow_version 2.x
except Exception:
pass
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import os
그 다음 데이터를 불러오고, 데이터 셋업 작업을 해 준다. 로이터 뉴스 데이터셋은 keras.datasets 패키지 안에 들어 있다.
# 로이터 뉴스 데이터셋 불러오기
from keras.datasets import reuters
from keras.models import Sequential
from keras.layers import Dense, LSTM, Embedding
from keras.preprocessing import sequence
from keras.utils import np_utils
# seed 값 설정
seed = 0
np.random.seed(seed)
tf.compat.v1.set_random_seed(3)
# 불러온 데이터를 학습셋(80%), 테스트셋(20%)으로 나누기
(X_train, Y_train), (X_test, Y_test) = reuters.load_data(num_words=1500, test_split=0.2)
# 데이터 확인하기
category = np.max(Y_train) + 1
print(category, '카테고리')
print(len(X_train), '학습용 뉴스 기사')
print(len(X_test), '테스트용 뉴스 기사')
print(X_train[0])
print(Y_train[0])랜덤으로 시드값을 준 다음에 학습셋, 테스트셋을 나눠 준다.
load_data할 때 num_words 수치는 여러 가지로 테스트해봤다. 500으로 해봤을 때는 loss값이 빨리 떨어지지 않고, 1000은 평이한 수준이었고, 1500은 1000과 비슷하거나 약간 더 나은 수준이라 1500으로 했다. test_split 옵션은 전체 데이터셋 중 학습이 아닌 테스트하는 데이터 비중을 얼마나 줄 것인지 정하는 것이다. 보통 학습 8:테스트 2 정도로 하니 0.2로 한다.
실행 결과는 다음과 같다. 카테고리는 46개이고, 학습용으로 8982개, 테스트용으로 2246개 기사가 있다.

get_word_index()로 단어와 거기 부여된 인덱스를 딕셔너리 형식으로 받아서 word_to_index에 넣는다.
그 다음, 인덱스의 실제 단어를 확인하기 위해 빈 딕셔너리 index_to_word를 만들어 인덱스와 실제 단어를 확인한다.
word_to_index = reuters.get_word_index() # 단어와 그 단어에 부여된 인덱스를 리턴
print(word_to_index)
print(len(word_to_index))
index_to_word = {}
for key, value in word_to_index.items():
index_to_word[value] = key # 인덱스의 실제 단어를 확인
print(' '.join([index_to_word[X] for X in X_train[0]]))실행 결과는 다음과 같다.

pyplot으로 히스토그램 그래프를 한 번 만들어서 뉴스 샘플의 기사는 몇 개 단어로 이뤄져 있는지 확인해 보자.
print('뉴스 기사의 최대 길이 :{}'.format(max(len(l) for l in X_train)))
print('뉴스 기사의 평균 길이 :{}'.format(sum(map(len, X_train))/len(X_train)))
plt.hist([len(s) for s in X_train], bins=50)
plt.xlabel('length of samples')
plt.ylabel('number of samples')
plt.show()
데이터 전처리를 해보자.
sequence.pad_sequences는 데이터셋의 길이가 일정하지 않을 때 사용한다. 여기서는 maxlen을 500으로 맞춰서 최대 500까지만 허용하도록 해 보자. 학습셋과 데이터셋 모두에 동일하게 적용한다. np_utils.to_categorical은 원-핫 인코딩을 해 주는 함수이다. 원-핫 인코딩은 10진 정수 형식의 데이터를 2진수 형식으로 변경해 주는데, 매개변수 크기만큼 0으로 된 배열을 만들되 파라미터 값 위치에만 1을 넣어 주는 것이다.
가령 np_utils.to_categorical(Y_train)을 하면 Y_train(정수) 크기만큼 0으로 된 배열을 만든 뒤 마지막에 1을 추가하는 것이다. 인자가 2개(x, y)일 때는 x가 파라미터 위치가 되고, y는 배열 크기가 된다.
# 데이터 전처리
# maxlen 수정
x_train = sequence.pad_sequences(X_train, maxlen=500)
x_test = sequence.pad_sequences(X_test, maxlen=500)
y_train = np_utils.to_categorical(Y_train)
y_test = np_utils.to_categorical(Y_test)잘 됐는지 확인해 보자.
학습셋 각 요소의 길이만을 담은 리스트를 s_len이라고 하자. 이 요소 길이를 다시 루프를 돌리는데, 이번에는 요소 길이가 500보다 작거나 같은 것만 세서 500보다 작거나 같으면 1, 아니면 0으로 계산한 것을 sum으로 구한다.
쉽게 말해, 2번 라인은 학습셋 각 요소의 길이들 중 500보다 작거나 같은 요소의 개수만 세서 출력한다.
3번 라인은 위의 조건을 만족하는 요소들이 전체 데이터셋 중 몇 퍼센트나 되는지 출력한다.
s_len = [len(s) for s in X_train]
print(sum([int(i<=500) for i in s_len]))
print(sum([int(i<=500) for i in s_len])/len(X_train))
print(np.shape(x_train))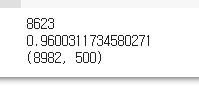
학습셋 중 길이가 500 이하인 요소는 8623개이고, 그것은 전체 데이터셋 중 약 96%를 차지한다. 학습셋 전체 개수가 8982개였으니 계산이 맞다. 이제 학습셋은 총 8982개, 원핫 인코딩으로 500으로 길이가 맞춰진 2차원 numpy 배열이다.
(1) 단순 RNN
# 1. 기본 RNN 모델
# 모델의 설정
model = tf.keras.Sequential([
tf.keras.layers.Embedding(input_dim=30000, output_dim=150, input_length=500),
# 모델 설계
tf.keras.layers.SimpleRNN(units=46, return_sequences=False, input_shape=[500, 150]),
tf.keras.layers.Dense(46, activation='softmax')
])
# 모델의 컴파일
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
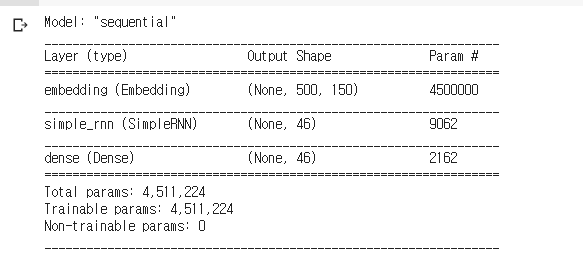
model.summary()tf.keras.Sequential은 모델 설계하는 메소드이므로 설명을 생략한다.
자연어 데이터를 처리하는 것이기 때문에 tf.keras.layers.Embedding 레이어(층)는 필수다. 자연어를 수치화된 정보로 바꾸는 레이어이다. input_dim은 가능한 토큰 개수, output_dim은 임베딩 차원, input_length는 입력 시퀀스 길이다.
임베딩 먼저 해 준 다음에는 RNN, LSTM 등 사용이 가능하다. 제일 기본적인 RNN을 써 보자.
tf.keras.layers.SimpleRNN 레이어를 추가하면 된다. units은 출력 수인데, 카테고리가 46개이므로 46으로 해 주고, return_sequences는 hidden state 출력 여부이다. 재귀적으로 반복할 것인지를 묻는 것인데 일단 False로 한다. 그 다음 dense 레이어를 얹어주는데 다음에 레이어가 없으므로 자동으로 출력층이 되고, 입력은 46(위에 SimpleRNN 레이어에서의 출력 수와 같다), 출력층이니 활성화 함수를 정해줘야 하는데 이는 softmax를 쓰기로 한다.
모델을 만들었으면 컴파일을 해야 한다. categorical_crossentropy로 손실 함수를 정하고, 최적화는 adam으로 한다.
결과는 다음과 같다.
이제 모델 fit으로 학습을 진행하고 결과를 보겠다. 코드는 다음과 같다. 앞으로 소개할 LSTM, CNN+LSTM, GRU 모두 학습 코드 뭉치는 아래와 똑같다.
# 모델의 실행
history = model.fit(x_train, y_train, epochs=15, batch_size=32, validation_data=(x_test, y_test))
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(history.history['loss'], 'b-', label='loss')
plt.plot(history.history['val_loss'], 'r--', label='val_loss')
plt.xlabel('Epoch')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(history.history['accuracy'], 'g-', label='accuracy')
plt.plot(history.history['val_accuracy'], 'k--', label='val_accuracy')
plt.xlabel('Epoch')
plt.legend()
plt.show()model.fit epochs는 15를 주고, batch_size는 64도 줘 봤는데 32가 결과가 더 나아서 32로 줘 봤다.
그 다음 pyplot으로 그래프를 그려 결과를 본다. loss가 낮고, accuracy가 높다고 무조건 좋은 것은 아니다. 과적합이 됐다면 val_loss는 오히려 상승하고, val_accuracy는 오히려 떨어지기 때문이다. 어느 임계점이 지나 val_loss와 val_accuracy가 우리가 바라는 방향과 반대로 진행한다면 epochs를 조정하거나 batch_size를 조정하는 식으로 해결을 봐야 한다.
SimpleRNN의 경우 epochs를 15로 주면 시간이 정말 오래 걸린다. -_- 1epoch당 평균 100초 정도가 걸린다. 1500초, 즉 25분 정도가 걸린다. 다른 할 일이 있어 할 만했지만, 어차피 SimpleRNN은 버리는 카드나 마찬가지므로 5 epoch 정도로 해결을 봐도 될 것 같다.

보다시피 loss는 뚝뚝 떨어지지만(딱히 좋아할 일만은 아니다) 1 밑으로 떨어지지는 못 하고, val_loss는 올랐다 떨어졌다를 반복한다. 우측의 accuracy 그래프를봐도 accuracy는 그냥 올라가지만 val_accuracy는 꾸준히 상승하지 못한다. SimpleRNN만으로는 학습을 많이 해도 별 효과가 없고 과적합되기 쉽다.
(2) LSTM
다음은 LSTM이다. LSTM은 위에서 설명한 것과 같이 RNN과 달리 이전에 들어온 값에 대한 정보를 유지하기 위해 게이트라는 가중치를 추가하게 된다. Gradient Vanishing 문제를 막는 것이다.
# 2. LSTM
# 모델의 설정
model = tf.keras.Sequential([
tf.keras.layers.Embedding(input_dim=30000, output_dim=150, input_length=500),
# 모델 설계
tf.keras.layers.LSTM(units=46),
tf.keras.layers.Dense(46, activation='softmax')
])
# 모델의 컴파일 (sparse를 써보려고 했는데 실패함)
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.summary()임베딩 레이어는 SimpleRNN에서 쓴 레이어와 동일하니 설명은 생략한다.
tf.keras.layers.LSTM이 바로 LSTM 레이어이다. return_sequences는 기본적으로 False이기 때문에 따로 표시하지는 않았다. LSTM 층에는 단순하게 units 수만 적어줬다. Dense에서도 이전 층 출력인 46으로 받는다. 출력층이니 활성화 함수를 정해주는데 역시 softmax이다. 컴파일에서는 다른 손실 함수를 써보려고 했지만 실패해서 SimpleRNN과 똑같이 썼다.

이제 학습을 해 보자.

loss와 val_loss가 거의 비슷하게 떨어진다. accuracy와 val_accuracy도 비슷하게 떨어진다. 학습이 잘 되고 있음을 보여 준다. val_loss 1.11, val_accuracy 0.74이다. 또한 에포크당 20초라서 똑같이 15 epochs를 학습해도 SimpleRNN보다 학습 과정이 빠르다.
(3) CNN + LSTM
다음은 CNN + LSTM이다. CNN이라니 무슨 뜻일까? 원핫 인코딩을 거친 데이터는 배열이 된다는 것을 위에서 짚고 넘어갔다. 이 1차원 배열에 대해 컨볼루션을 적용하고 LSTM 레이어를 연결하는 것이 CNN + LSTM 조합이다. 보통 임베딩 후 CNN 연산하듯 Dropout도 하고, Conv1D 레이어를 쓰고 Pooling1D도 한다. CNN은 이미지 컨볼루션에 자주 쓰이는 모델이다. Fashion MNIST 같은 데이터셋을 분류할 때는 Conv2D 레이어(이미지는 가로/세로 2차원 배열이니까)를 자주 썼지만, 이 경우는 텍스트라서 Conv1D 연산을 할 수 있다. 역시 텍스트라서 풀링도 1D로 해준다.
# 2. CNN + LSTM
# 모델의 설정
model = tf.keras.Sequential([
tf.keras.layers.Embedding(input_dim=30000, output_dim=200, input_length=500),
# 모델 설계
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Conv1D(64, 5, padding='valid', activation='relu', strides=1),
tf.keras.layers.MaxPooling1D(pool_size=3),
tf.keras.layers.LSTM(units=46),
tf.keras.layers.Dense(46, activation='softmax')
])
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.summary()임베딩 레이어에서 output_dim을 200으로 바꿔 봤다. 사실 별 큰 의미는 없고, 어떻게든 accuracy를 좀 높여보려고 수치를 조정하다가 만져 본 것이다. 그런 다음 Dropout을 해서 epoch마다 절반의 데이터만 새로 갖고 학습을 하도록 했다. Conv1D 레이어를 추가해서 컨볼루션 연산을 하도록 하고, 그 다음 MaxPooling으로 영상 크기를 줄인다. 여기서는 1차원이니 배열 요소 개수를 줄이는 것이다. 그 다음에 비로소 LSTM 레이어와 출력층이 나온다. 이 뒤로는 앞의 코드와 똑같아서 설명을 생략하겠다.
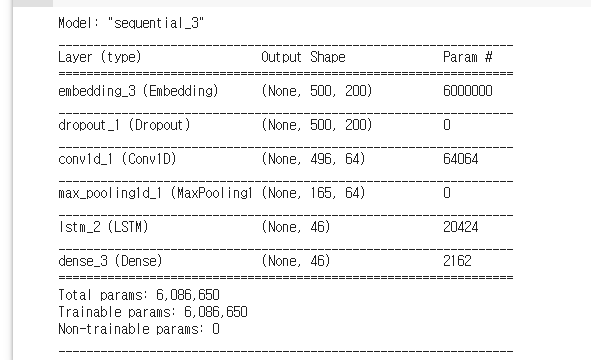
학습을 진행해 보자.

LSTM과 비슷하게 학습이 잘 되고 있다. val_loss 0.94, val_accuracy 0.78. LSTM보다 val_loss는 조금 더 떨어진 모습이다. LSTM과 비슷하게 1 epoch 당 20초 정도 소요되어 학습은 빠른 편이다.
(4) GRU
GRU는 Gated Recurrent Unit의 줄임말이다. LSTM과 비슷하지만, 구조가 더 간단해서 계산상으로 효율적이라고 한다. LSTM에서의 셀 상태(cell state) 역할의 c가 없다. GRU에는 Update Gate와 Reset Gate 2가지만 존재한다. 기존 LSTM에서 사용되는 셀 상태 계산(은닉 상태 업데이트)을 줄이는 효과가 있다.
내부적으로 sigmod 함수 2번과 tanh 활성화함수 1번을 사용한다.
# 3. GRU
# 모델의 설정
model = tf.keras.Sequential([
tf.keras.layers.Embedding(input_dim=30000, output_dim=200, input_length=500),
# 모델 설계
tf.keras.layers.GRU(units=64, return_sequences=True, input_shape=[500,200]),
tf.keras.layers.GRU(units=46),
tf.keras.layers.Dense(46, activation='softmax')
])
# 모델의 컴파일
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.summary()

학습해 보자.

10 에포크가 지나자 살짝 과적합의 조짐이 보인다. val_accuracy도 의미있게 상승하지 않는다. 최종 결과는 val_loss 1.03, val_accuracy 0.78이다.
이렇게 해서 자연어 데이터를 다루는 모델 4가지를 살펴 봤다. CNN + LSTM 모델이 효과가 제일 좋았다. 물론 모델 설계를 정교하게 하고, fit 과정에서 epochs나 batch_size를 조정하는 등의 조작을 한다면 loss는 더 낮고, accuracy는 더 높게 얻을 수 있을 것 같다.
'개발일지' 카테고리의 다른 글
| 2021 졸업 작품 소개 (4) | 2021.12.30 |
|---|---|
| 2021 졸업 작품 개발 일지 (0) | 2021.12.30 |
| [생존형 튜토리얼] 파이썬 selenium으로 데이터 크롤링 (0) | 2021.02.15 |
| 커피창고 심리테스트 작업기 (5) | 2020.11.05 |
| 카카오 지도 API로 엑셀 파일의 시설물 위치 지도에 마커 찍기 (4) | 2020.09.23 |



